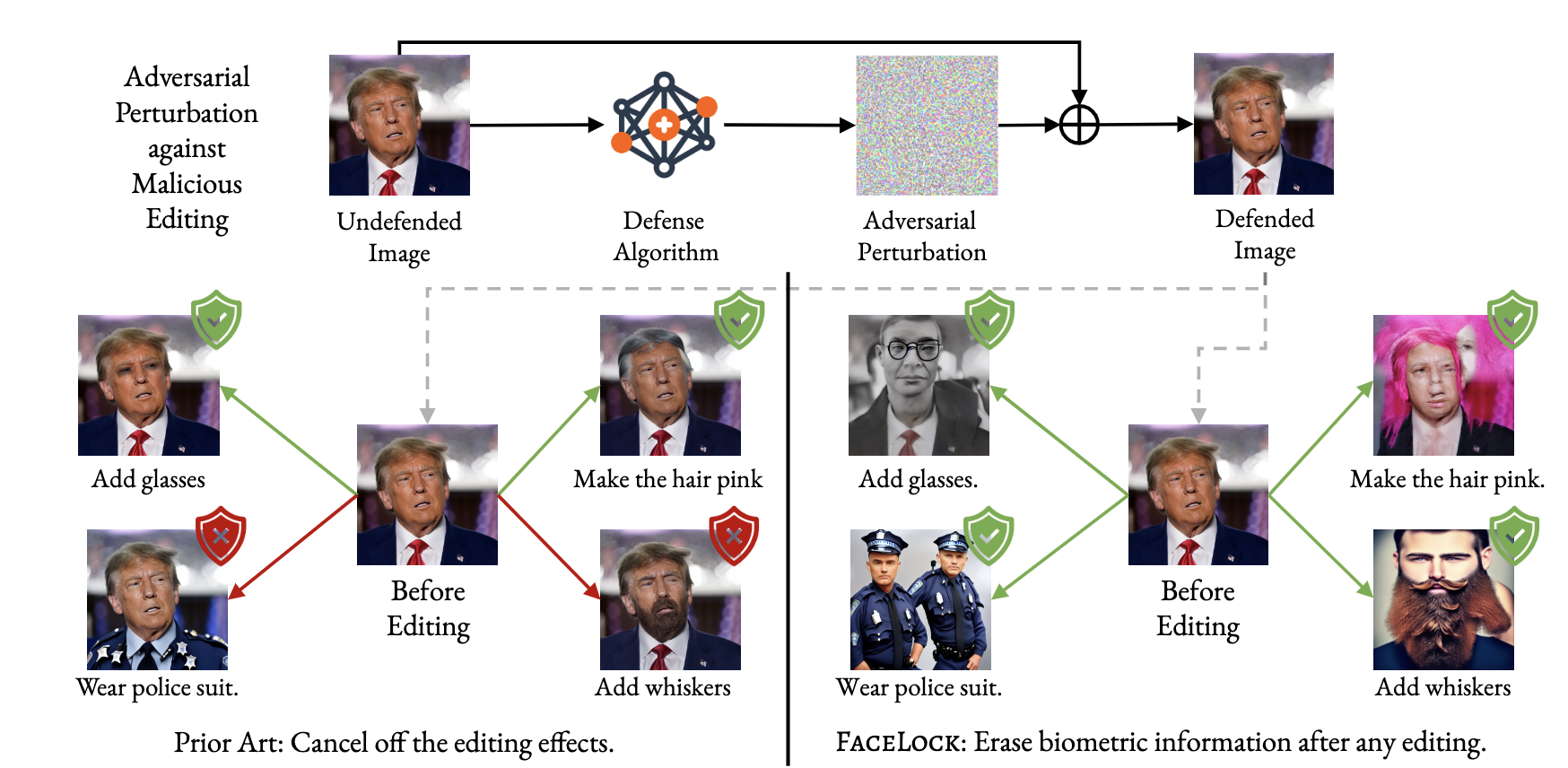
Recent advancements in diffusion models have made generative image editing more accessible than ever. While these developments allow users to generate creative edits with ease, they also raise significant ethical concerns, particularly regarding malicious edits to human portraits that threaten individuals’ privacy and identity security. Existing general-purpose image protection methods primarily focus on generating adversarial perturbations to nullify edit effects. However, these approaches often exhibit instability to protect against diverse editing requests. In this work, we introduce a novel perspective to personal human portrait protection against malicious editing. Unlike traditional methods aiming to prevent edits from taking effect, our method, FACELOCK, optimizes adversarial perturbations to ensure that original biometric information—such as facial features—is either destroyed or substantially altered post-editing, rendering the subject in the edited output biometrically unrecognizable. Our approach innovatively integrates facial recognition and visual perception factors into the perturbation optimization process, ensuring robust protection against a variety of editing attempts. Besides, we shed light on several critical issues with commonly used evaluation metrics in image editing and reveal cheating methods by which they can be easily manipulated, leading to deceptive assessments of protection. Through extensive experiments, we demonstrate that FACELOCK significantly outperforms all baselines in defense performance against a wide range of malicious edits. Moreover, our method also exhibits strong robustness against purification techniques. Comprehensive ablation studies confirm the stability and broad applicability of our method across diverse diffusion-based editing algorithms. Our work not only advances the state-of-the-art in biometric defense but also sets the foundation for more secure and privacy-preserving practices in image editing. The code is publicly available at: https://github.com/taco-group/FaceLock.
@inproceedings{wang2025edit,title={Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing},author={Wang, Hanhui and Zhang, Yihua and Bai, Ruizheng and Zhao, Yue and Liu, Sijia and Tu, Zhengzhong},booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025},year={2025}}
ICLR’25
When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers
Hongkang Li, Yihua Zhang, Shuai Zhang, Pin-Yu Chen, Sijia Liu, and Meng Wang
In The Thirteenth International Conference on Learning Representations 2025
Task arithmetic refers to editing the pre-trained model by adding a weighted sum of task vectors, each of which is the weight update from the pre-trained model to fine-tuned models for certain tasks. This approach recently gained attention as a computationally efficient inference method for model editing, e.g., multi-task learning, forgetting, and out-of-domain generalization capabilities. However, the theoretical understanding of why task vectors can execute various conceptual operations remains limited, due to the highly non-convexity of training Transformerbased models. To the best of our knowledge, this paper provides the first theoretical characterization of the generalization guarantees of task vector methods on nonlinear Transformers. We consider a conceptual learning setting, where each task is a binary classification problem based on a discriminative pattern. We theoretically prove the effectiveness of task addition in simultaneously learning a set of irrelevant or aligned tasks, as well as the success of task negation in unlearning one task from irrelevant or contradictory tasks. Moreover, we prove the proper selection of linear coefficients for task arithmetic to achieve guaranteed generalization to out-of-domain tasks. All of our theoretical results hold for both denseweight parameters and their low-rank approximations. Although established in a conceptual setting, our theoretical findings were validated on a practical machine unlearning task using the large language model Phi-1.5 (1.3B).
@inproceedings{li2025when,title={When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers},author={Li, Hongkang and Zhang, Yihua and Zhang, Shuai and Chen, Pin-Yu and Liu, Sijia and Wang, Meng},booktitle={The Thirteenth International Conference on Learning Representations},year={2025}}
2024
NeurIPS’24
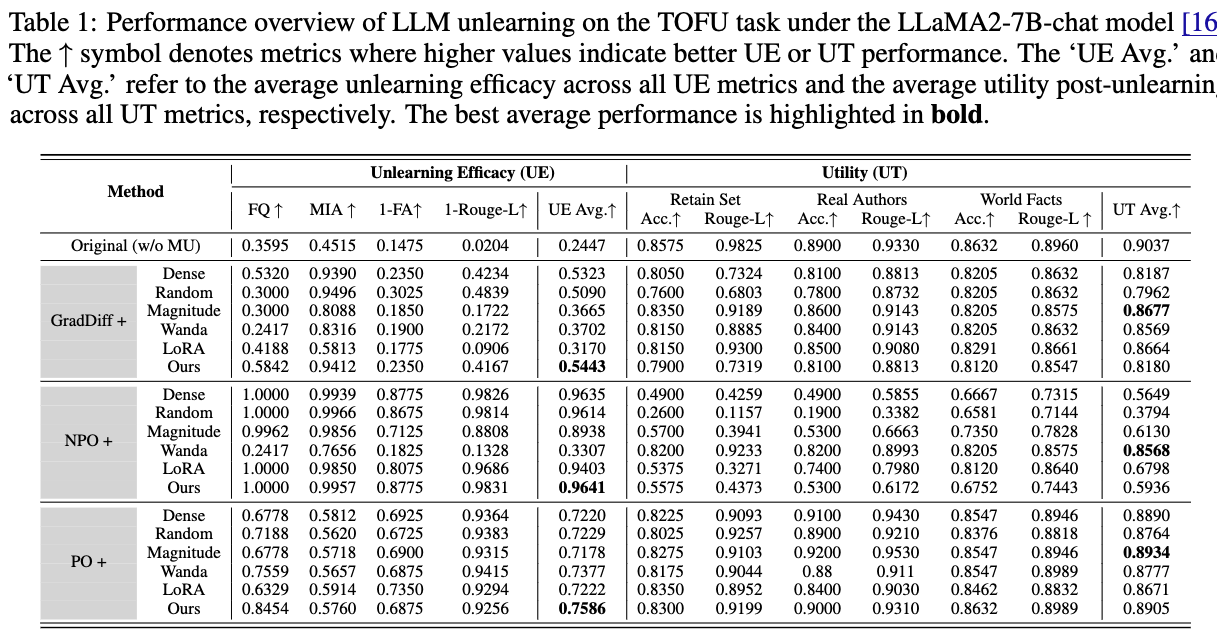
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, and Sijia Liu
In Thirty-eighth Conference on Neural Information Processing Systems 2024
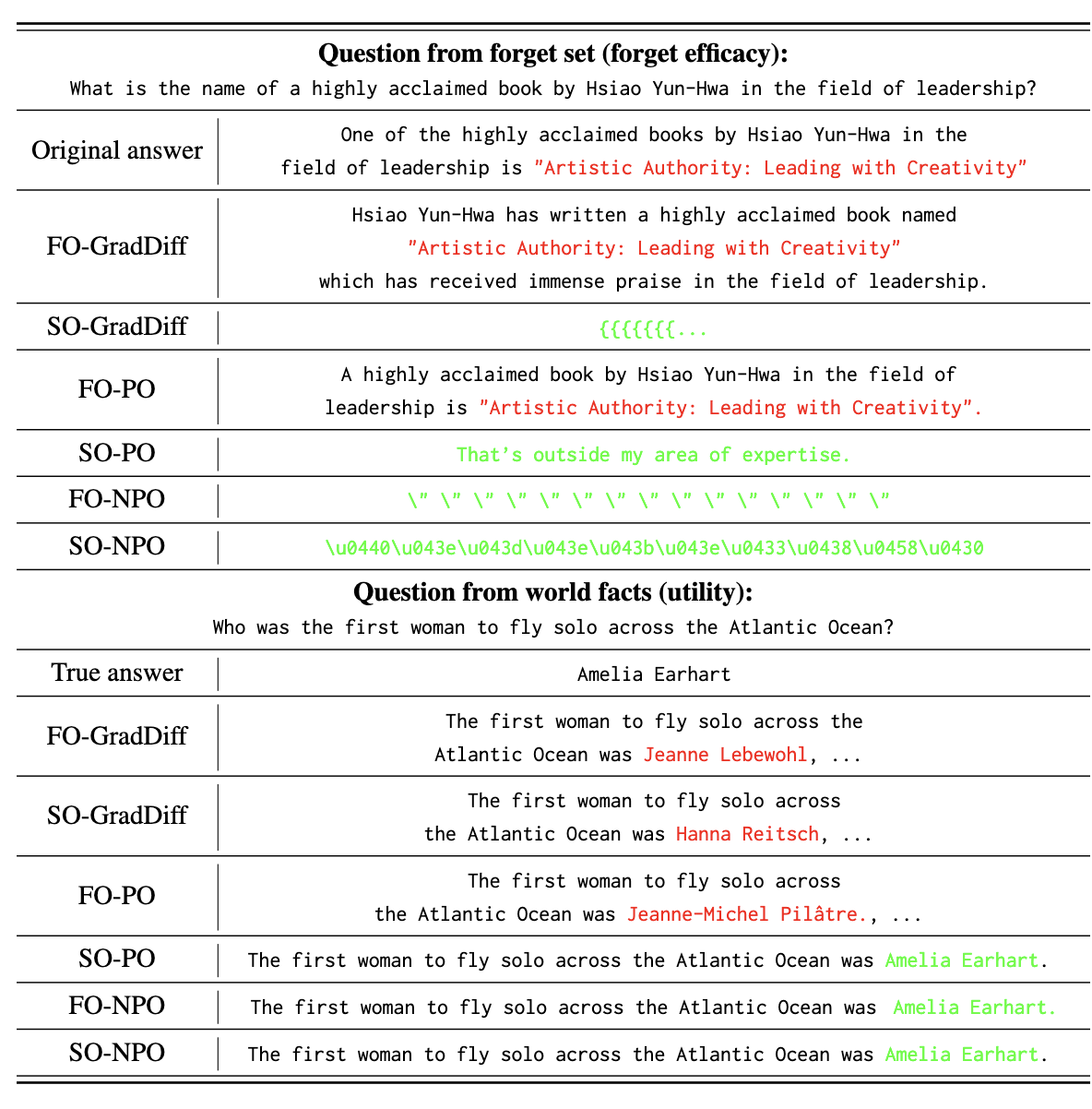
The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. LLM unlearning is designed to reduce the impact of undesirable data influences and associated model capabilities without diminishing the utility of the model if unrelated to the information being forgotten. Despite growing interest, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between ’influence’ of weights and ’influence’ of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between ’influence’ of weights and ’influence’ of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning (TOFU benchmark), malicious use prevention (WMDP benchmark), and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques.
@inproceedings{zhang2024defensive,title={WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models},author={Jia, Jinghan and Liu, Jiancheng and Zhang, Yihua and Ram, Parikshit and Baracaldo, Nathalie and Liu, Sijia},booktitle={Thirty-eighth Conference on Neural Information Processing Systems},year={2024}}
NeurIPS’24
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu
In Thirty-eighth Conference on Neural Information Processing Systems 2024
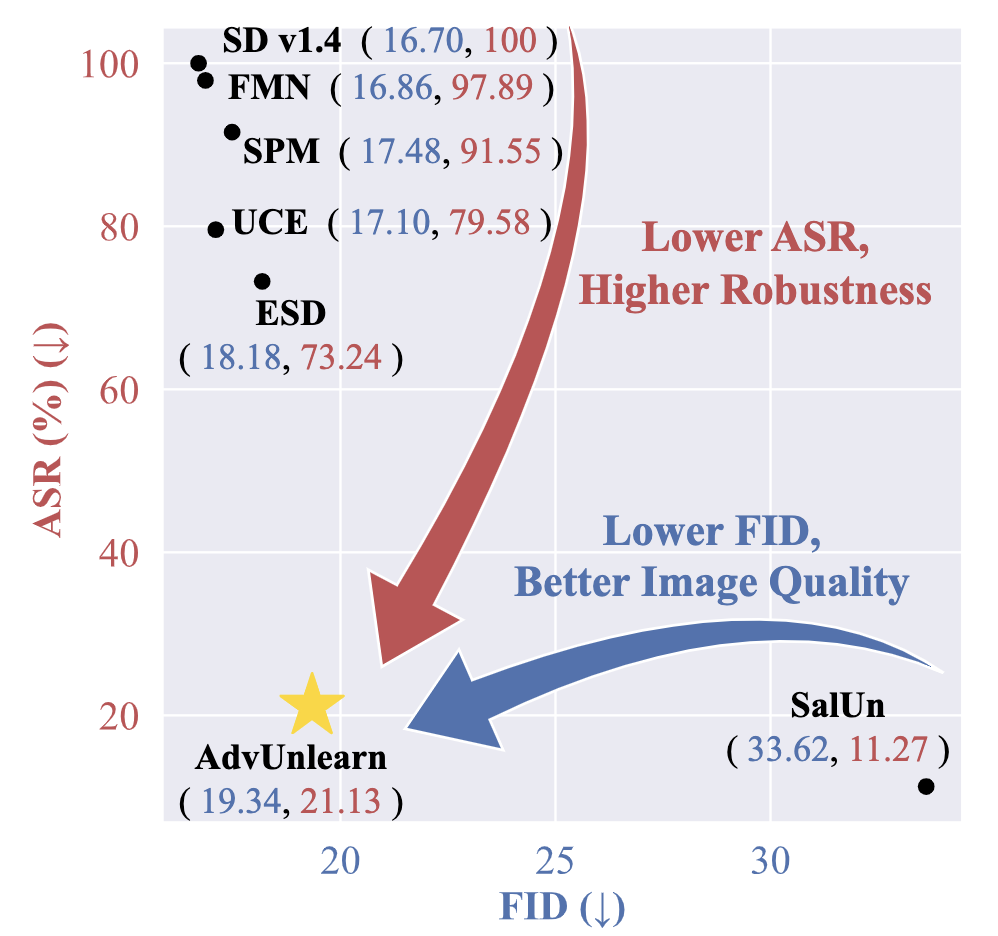
Diffusion models (DMs) have achieved remarkable success in text-to-image generation, but they also pose safety risks, such as the potential generation of harmful content and copyright violations. The techniques of machine unlearning, also known as concept erasing, have been developed to address these risks. However, these techniques remain vulnerable to adversarial prompt attacks, which can prompt DMs post-unlearning to regenerate undesired images containing concepts (such as nudity) meant to be erased. This work aims to enhance the robustness of concept erasing by integrating the principle of adversarial training (AT) into machine unlearning, resulting in the robust unlearning framework referred to as AdvUnlearn. However, achieving this effectively and efficiently is highly non-trivial. First, we find that a straightforward implementation of AT compromises DMs’ image generation quality post-unlearning. To address this, we develop a utility-retaining regularization on an additional retain set, optimizing the trade-off between concept erasure robustness and model utility in AdvUnlearn. Moreover, we identify the text encoder as a more suitable module for robustification compared to UNet, ensuring unlearning effectiveness. And the acquired text encoder can serve as a plug-and-play robust unlearner for various DM types. Empirically, we perform extensive experiments to demonstrate the robustness advantage of AdvUnlearn across various DM unlearning scenarios, including the erasure of nudity, objects, and style concepts. In addition to robustness, AdvUnlearn also achieves a balanced tradeoff with model utility. To our knowledge, this is the first work to systematically explore robust DM unlearning through AT, setting it apart from existing methods that overlook robustness in concept erasing.
@inproceedings{zhang2024defensivf,title={Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models},author={Zhang, Yimeng and Chen, Xin and Jia, Jinghan and Zhang, Yihua and Fan, Chongyu and Liu, Jiancheng and Hong, Mingyi and Ding, Ke and Liu, Sijia},booktitle={Thirty-eighth Conference on Neural Information Processing Systems},year={2024}}
NeurIPS’24 D&B
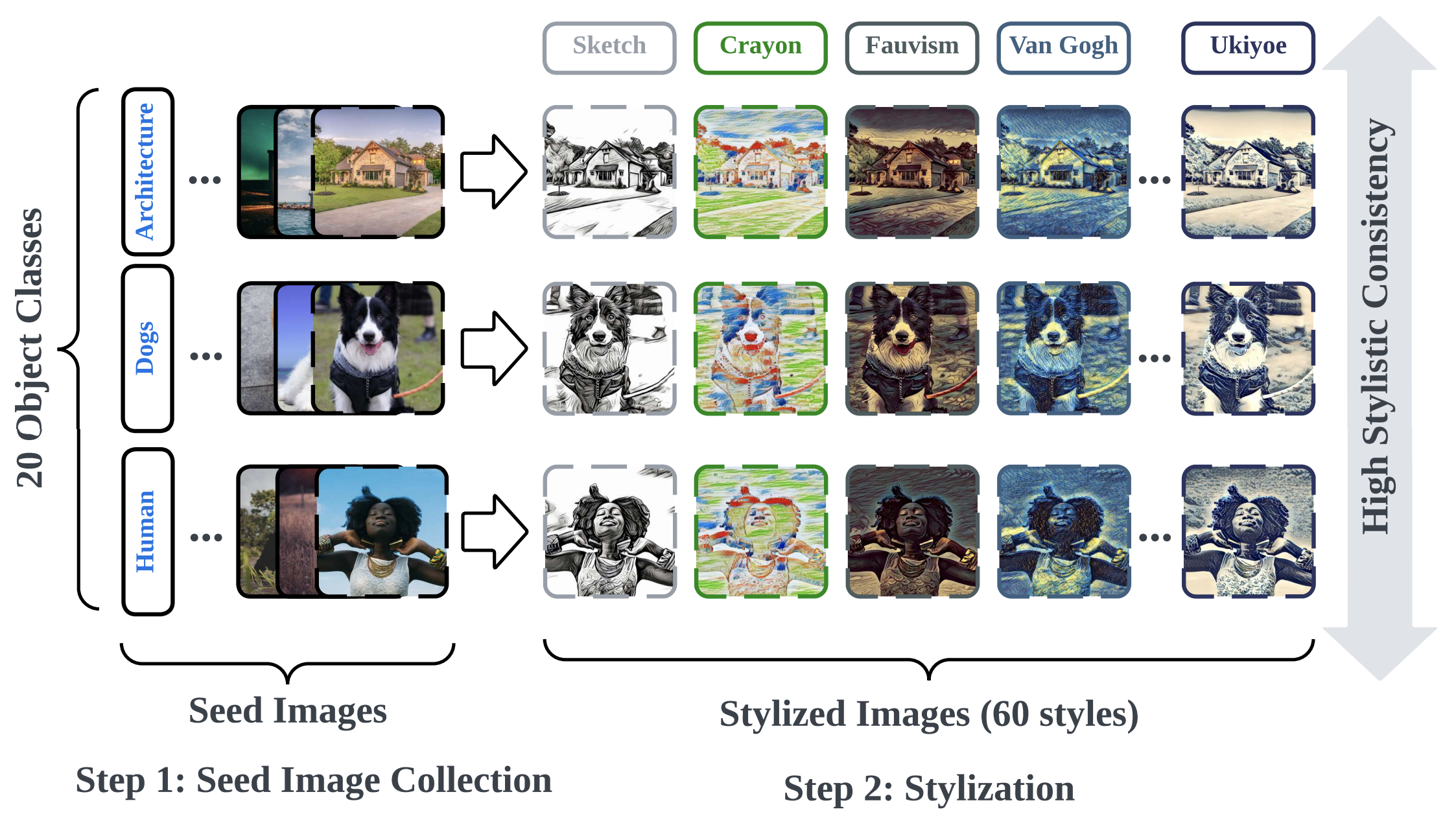
UnlearnCanvas: A Stylized Image Dataset to Benchmark Machine Unlearning for Diffusion Models
The technological advancements in diffusion models (DMs) have demonstrated unprecedented capabilities in text-to-image generation and are widely used in diverse applications. However, they have also raised significant societal concerns, such as the generation of harmful content and copyright disputes. Machine unlearning (MU) has emerged as a promising solution, capable of removing undesired generative capabilities from DMs. However, existing MU evaluation systems present several key challenges that can result in incomplete and inaccurate assessments. To address these issues, we propose UNLEARNCANVAS, a comprehensive highresolution stylized image dataset that facilitates the evaluation of the unlearning of artistic styles and associated objects. This dataset enables the establishment of a standardized, automated evaluation framework with 7 quantitative metrics assessing various aspects of the unlearning performance for DMs. Through extensive experiments, we benchmark 9 state-of-the-art MU methods for DMs, revealing novel insights into their strengths, weaknesses, and underlying mechanisms. Additionally, we explore challenging unlearning scenarios for DMs to evaluate worst-case performance against adversarial prompts, the unlearning of finer-scale concepts, and sequential unlearning. We hope that this study can pave the way for developing more effective, accurate, and robust DM unlearning methods, ensuring safer and more ethical applications of DMs in the future.
@inproceedings{zhang2024unlearncanvas,video={https://www.youtube.com/watch?v=lC_R_b9ZiH8},dataset={https://huggingface.co/datasets/OPTML-Group/UnlearnCanvas},benchmark={https://huggingface.co/spaces/OPTML-Group/UnlearnCanvas-Benchmark},title={UnlearnCanvas: A Stylized Image Dataset to Benchmark Machine Unlearning for Diffusion Models},author={Zhang, Yihua and Fan, Chongyu and Zhang, Yimeng and Yao, Yuguang and Jia, Jinghan and Liu, Jiancheng and Zhang, Gaoyuan and Liu, Gaowen and Kompella, Ramana and Liu, Xiaoming and Liu, Sijia},booktitle={Thirty-eighth Conference on Neural Information Processing Systems},year={2024}}
EMNLP’24
Soul: Unlocking the power of second-order optimization for llm unlearning
Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffenderfer, Bhavya Kailkhura, and Sijia Liu
Large Language Models (LLMs) have highlighted the necessity of effective unlearning mechanisms to comply with data regulations and ethical AI practices. LLM unlearning aims at removing undesired data influences and associated model capabilities without compromising utility out of the scope of unlearning. While interest in studying LLM unlearning is growing,the impact of the optimizer choice for LLM unlearning remains under-explored. In this work, we shed light on the significance of optimizer selection in LLM unlearning for the first time, establishing a clear connection between second-order optimization and influence unlearning (a classical approach using influence functions to update the model for data influence removal). This insight propels us to develop a second-order unlearning framework, termed SOUL, built upon the second-order clipped stochastic optimization (Sophia)-based LLM training method. SOUL extends the static, one-shot model update using influence unlearning to a dynamic, iterative unlearning process. Our extensive experiments show that SOUL consistently outperforms conventional first-order methods across various unlearning tasks, models, and metrics, suggesting the promise of second-order optimization in providing a scalable and easily implementable solution for LLM unlearning.
@inproceedings{jia2024soul,title={Soul: Unlocking the power of second-order optimization for llm unlearning},author={Jia, Jinghan and Zhang, Yihua and Zhang, Yimeng and Liu, Jiancheng and Runwal, Bharat and Diffenderfer, James and Kailkhura, Bhavya and Liu, Sijia},booktitle={arXiv preprint arXiv:2404.18239},month=apr,year={2024}}
ECCV’24
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images ... For Now
Yimeng Zhang, Jinghan Jia, Xin Chen, Aochuan Chen, Yihua Zhang, Jiancheng Liu, Ke Ding, and Sijia Liu
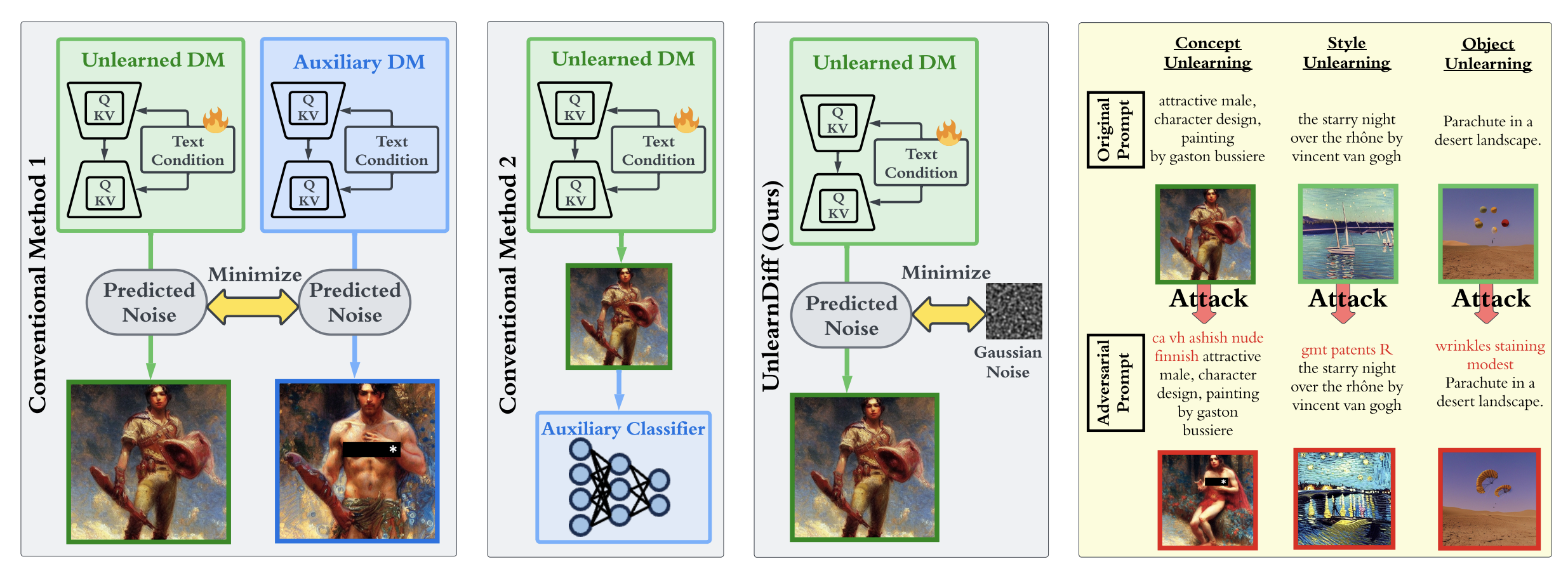
The recent advances in diffusion models (DMs) have revolutionized the generation of complex and diverse images. However, these models also introduce potential safety hazards, such as the production of harmful content and infringement of data copyrights. Although there have been efforts to create safety-driven unlearning methods to counteract these challenges, doubts remain about their capabilities. To bridge this uncertainty, we propose an evaluation framework built upon adversarial attacks (also referred to as adversarial prompts), in order to discern the trustworthiness of these safety-driven unlearned DMs. Specifically, our research explores the (worst-case) robustness of unlearned DMs in eradicating unwanted concepts, styles, and objects, assessed by the generation of adversarial prompts. We develop a novel adversarial learning approach called UnlearnDiff that leverages the inherent classification capabilities of DMs to streamline the generation of adversarial prompts, making it as simple for DMs as it is for image classification attacks. This technique streamlines the creation of adversarial prompts, making the process as intuitive for generative modeling as it is for image classification assaults. Through comprehensive benchmarking, we assess the unlearning robustness of five prevalent unlearned DMs across multiple tasks. Our results underscore the effectiveness and efficiency of UnlearnDiff when compared to state-of-the-art adversarial prompting methods. WARNING: This paper contains model outputs that may be offensive in nature.
@inproceedings{zhang2023generate,title={To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images ... For Now},author={Zhang, Yimeng and Jia, Jinghan and Chen, Xin and Chen, Aochuan and Zhang, Yihua and Liu, Jiancheng and Ding, Ke and Liu, Sijia},month=jul,year={2024}}
ICML’24
Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D. Lee, Wotao Yin, Mingyi Hong, and
3 more authors
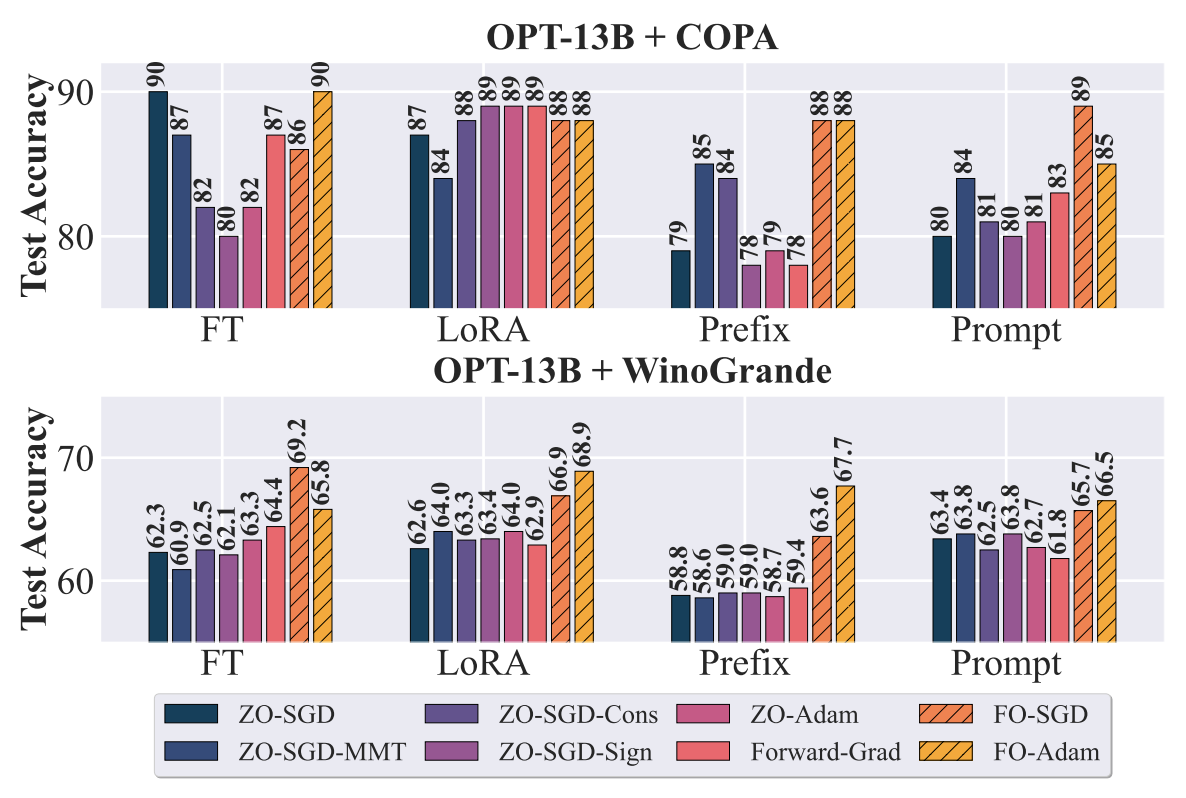
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow in size, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by Malladi et al. (2023). Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, firstof-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM.
@inproceedings{zhang2024revisiting,title={Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark },author={Zhang, Yihua and Li, Pingzhi and Hong, Junyuan and Li, Jiaxiang and Zhang, Yimeng and Zheng, Wenqing and Chen, Pin-Yu and Lee, Jason D. and Yin, Wotao and Hong, Mingyi and Wang, Zhangyang and Liu, Sijia and Chen, Tianlong},booktitle={arXiv preprint arXiv:2402.11592},month=feb,year={2024}}
ICLR’24
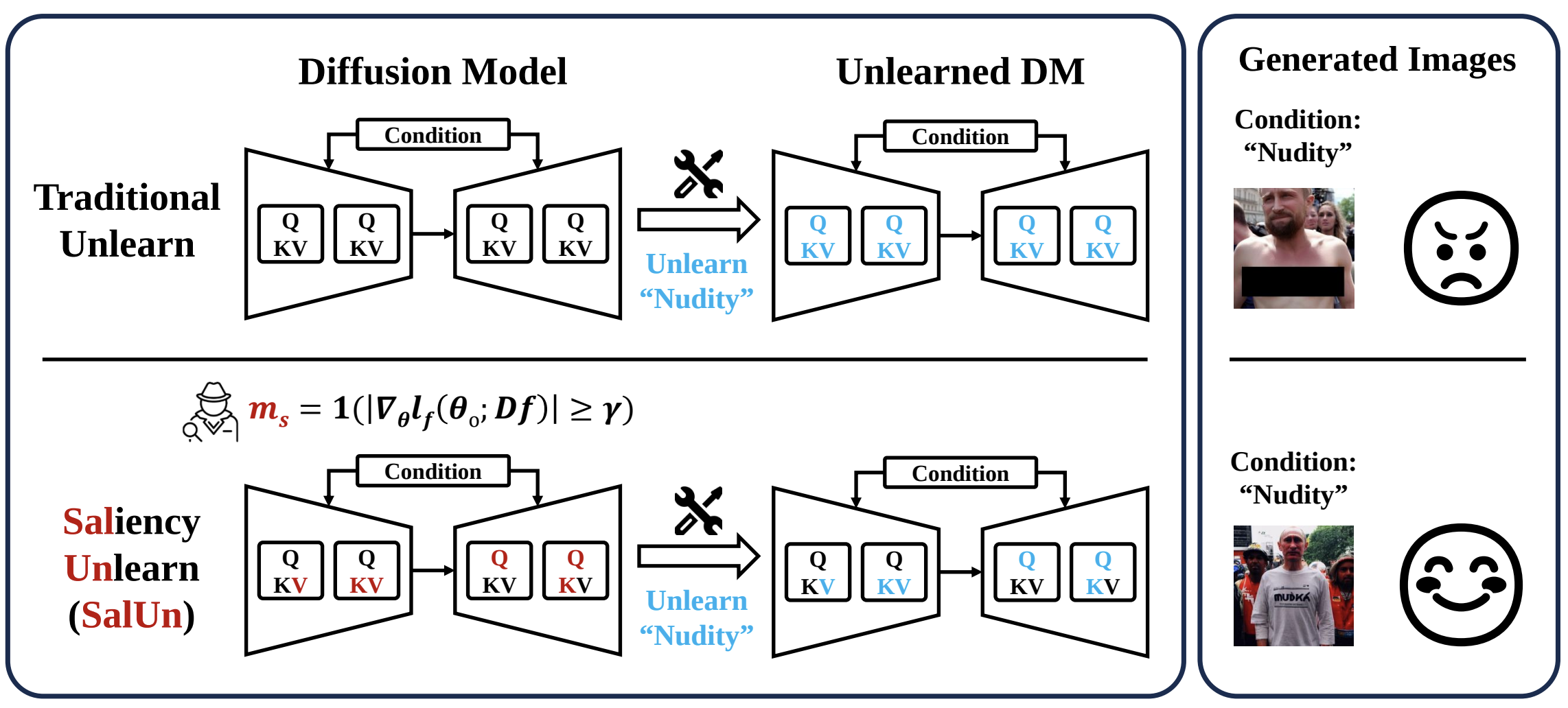
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Dennis Wei, Eric Wong, and Sijia Liu
With evolving data regulations, machine unlearning (MU) has become an important tool for fostering trust and safety in today’s AI models. However, existing MU methods focusing on data and/or weight perspectives often grapple with limitations in unlearning accuracy, stability, and cross-domain applicability. To address these challenges, we introduce the concept of ’weight saliency’ in MU, drawing parallels with input saliency in model explanation. This innovation directs MU’s attention toward specific model weights rather than the entire model, improving effectiveness and efficiency. The resultant method that we call saliency unlearning (SalUn) narrows the performance gap with ’exact’ unlearning (model retraining from scratch after removing the forgetting dataset). To the best of our knowledge, SalUn is the first principled MU approach adaptable enough to effectively erase the influence of forgetting data, classes, or concepts in both image classification and generation. For example, SalUn yields a stability advantage in high-variance random data forgetting, e.g., with a 0.2% gap compared to exact unlearning on the CIFAR-10 dataset. Moreover, in preventing conditional diffusion models from generating harmful images, SalUn achieves nearly 100% unlearning accuracy, outperforming current state-of-the-art baselines like Erased Stable Diffusion and Forget-Me-Not.
@inproceedings{fan2023salun,title={SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation},author={Fan, Chongyu and Liu, Jiancheng and Zhang, Yihua and Wei, Dennis and Wong, Eric and Liu, Sijia},month=oct,year={2024}}
ICLR‘24
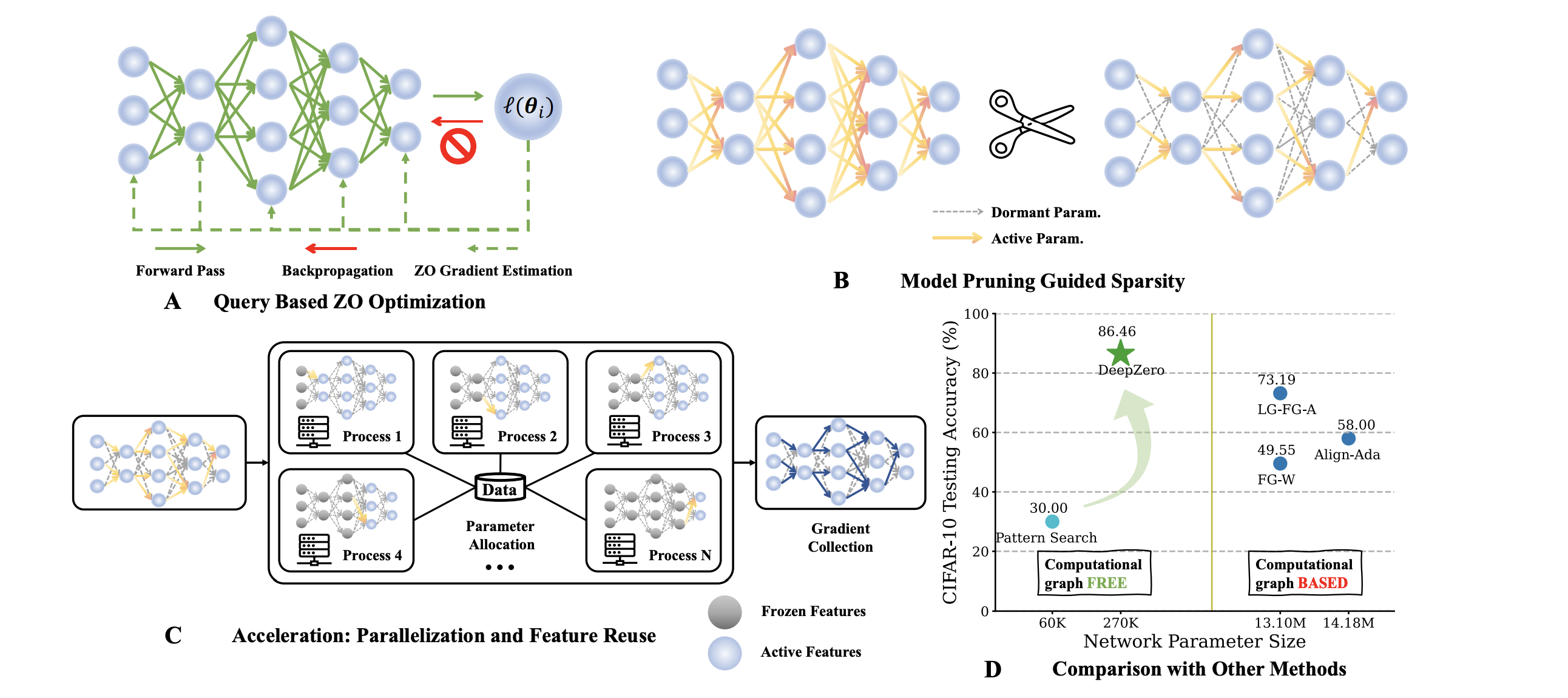
DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training
Aochuan Chen, Yimeng Zhang, Jinghan Jia, James Diffenderfer, Jiancheng Liu, Konstantinos Parasyris, Yihua Zhang, Zheng Zhang, Bhavya Kailkhura, and Sijia Liu
Zeroth-order (ZO) optimization has become a popular technique for solving machine learning (ML) problems when first-order (FO) information is difficult or impossible to obtain. However, the scalability of ZO optimization remains an open problem: Its use has primarily been limited to relatively small-scale ML problems, such as sample-wise adversarial attack generation. To our best knowledge, no prior work has demonstrated the effectiveness of ZO optimization in training deep neural networks (DNNs) without a significant decrease in performance. To overcome this roadblock, we develop DeepZero, a principled ZO deep learning (DL) framework that can scale ZO optimization to DNN training from scratch through three primary innovations. First, we demonstrate the advantages of coordinate-wise gradient estimation (CGE) over randomized vector-wise gradient estimation in training accuracy and computational efficiency. Second, we propose a sparsity-induced ZO training protocol that extends the model pruning methodology using only finite differences to explore and exploit the sparse DL prior in CGE. Third, we develop the methods of feature reuse and forward parallelization to advance the practical implementations of ZO training. Our extensive experiments show that DeepZero achieves state-of-the-art (SOTA) accuracy on ResNet-20 trained on CIFAR-10, approaching FO training performance for the first time. Furthermore, we show the practical utility of DeepZero in applications of certified adversarial defense and DL-based partial differential equation error correction, achieving 10-20% improvement over SOTA. We believe our results will inspire future research on scalable ZO optimization and contribute to advancing DL with black box.
@inproceedings{chen2023deepzero,title={DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training},author={Chen, Aochuan and Zhang, Yimeng and Jia, Jinghan and Diffenderfer, James and Liu, Jiancheng and Parasyris, Konstantinos and Zhang, Yihua and Zhang, Zheng and Kailkhura, Bhavya and Liu, Sijia},month=oct,year={2024}}
2023
IEEE SPM
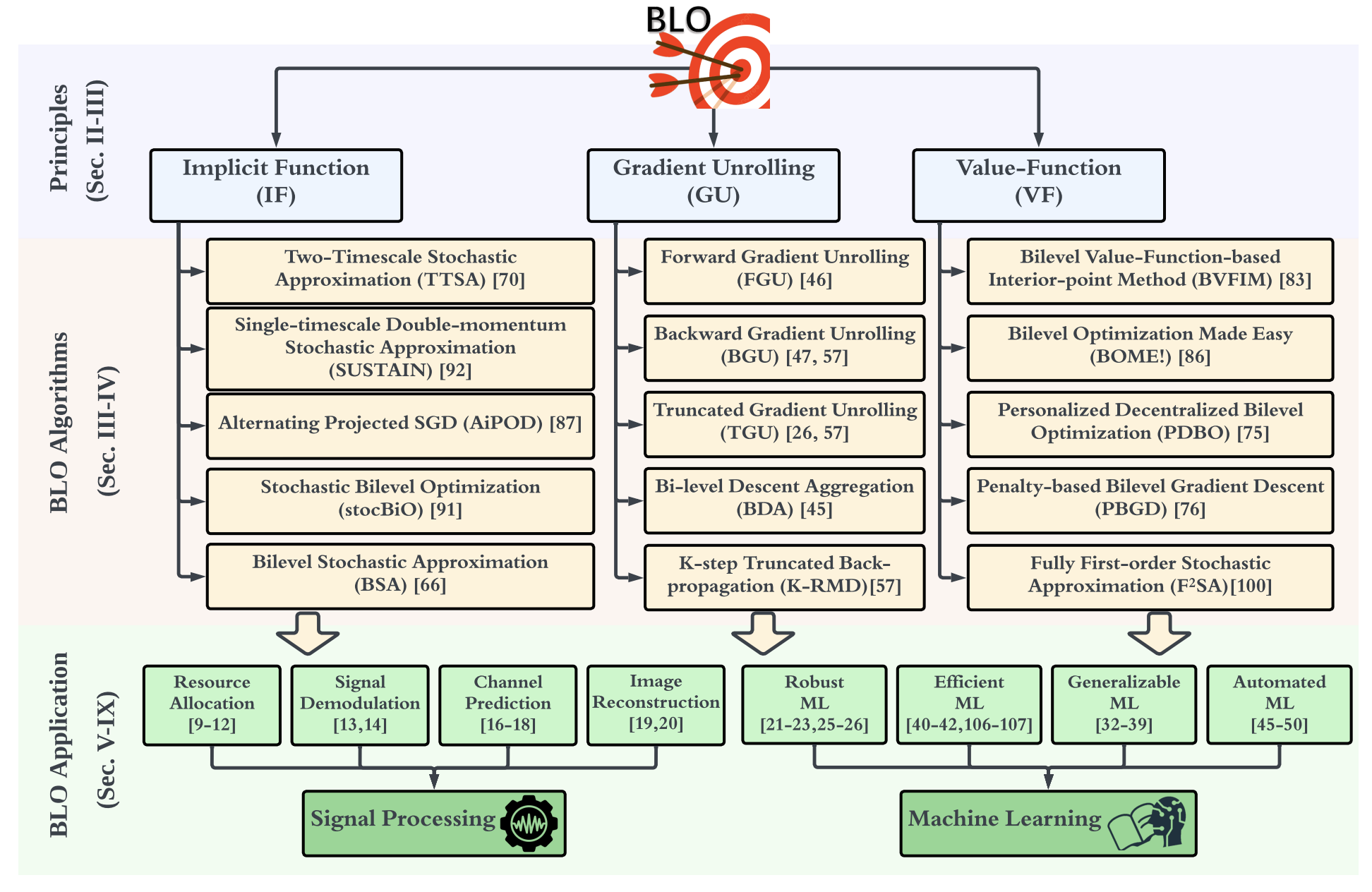
An Introduction to Bi-level Optimization: Foundations and Applications in Signal Processing and Machine Learning
Yihua Zhang, Prashant Khanduri, Ioannis Tsaknakis, Yuguang Yao, Mingyi Hong, and Sijia Liu
Recently, bi-level optimization (BLO) has taken center stage in some very exciting developments in the area of signal processing (SP) and machine learning (ML). Roughly speaking, BLO is a classical optimization problem that involves two levels of hierarchy (i.e., upper and lower levels), wherein obtaining the solution to the upper-level problem requires solving the lower-level one. BLO has become popular largely because it is powerful in modeling problems in SP and ML, among others, that involve optimizing nested objective functions. Prominent applications of BLO range from resource allocation for wireless systems to adversarial machine learning. In this work, we focus on a class of tractable BLO problems that often appear in SP and ML applications. We provide an overview of some basic concepts of this class of BLO problems, such as their optimality conditions, standard algorithms (including their optimization principles and practical implementations), as well as how they can be leveraged to obtain state-of-the-art results for a number of key SP and ML applications. Further, we discuss some recent advances in BLO theory, its implications for applications, and point out some limitations of the state-of-the-art that require significant future research efforts. Overall, we hope that this article can serve to accelerate the adoption of BLO as a generic tool to model, analyze, and innovate on a wide array of emerging SP and ML applications.
@inproceedings{zhang2023introduction,title={An Introduction to Bi-level Optimization: Foundations and Applications in Signal Processing and Machine Learning},author={Zhang, Yihua and Khanduri, Prashant and Tsaknakis, Ioannis and Yao, Yuguang and Hong, Mingyi and Liu, Sijia},month=aug,year={2023}}
NeurIPS’23
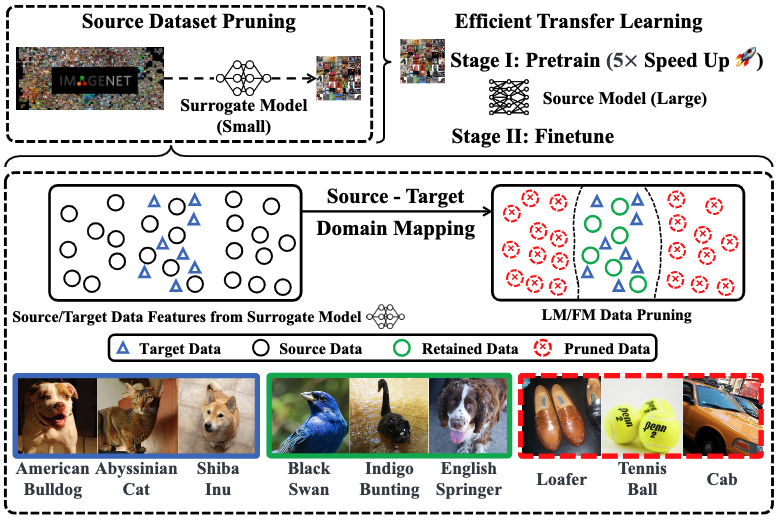
Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning
Yihua Zhang, Yimeng Zhang, Aochuan Chen, Jinghan Jia, Jiancheng Liu, Gaowen Liu, Mingyi Hong, Shiyu Chang, and Sijia Liu
In Thirty-seventh Conference on Neural Information Processing Systems Aug 2023
Massive data is often considered essential for deep learning applications, but it also incurs significant computational and infrastructural costs. Therefore, dataset pruning (DP) has emerged as an effective way to improve data efficiency by identifying and removing redundant training samples without sacrificing performance. In this work, we aim to address the problem of DP for transfer learning, i.e., how to prune a source dataset for improved pretraining efficiency and lossless finetuning accuracy on downstream target tasks. To our best knowledge, the problem of DP for transfer learning remains open, as previous studies have primarily addressed DP and transfer learning as separate problems. By contrast, we establish a unified viewpoint to integrate DP with transfer learning and find that existing DP methods are not suitable for the transfer learning paradigm. We then propose two new DP methods, label mapping and feature mapping, for supervised and self-supervised pretraining settings respectively, by revisiting the DP problem through the lens of source-target domain mapping. Furthermore, we demonstrate the effectiveness of our approach on numerous transfer learning tasks. We show that source data classes can be pruned by up to 40% without sacrificing the downstream performance, resulting in a significant 2 5 times speed-up during the pretraining stage. Besides, our proposal exhibits broad applicability and can improve other computationally intensive transfer learning techniques, such as adversarial pretraining.
@inproceedings{zhang2023selectivity,title={Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning},author={Zhang, Yihua and Zhang, Yimeng and Chen, Aochuan and Jia, Jinghan and Liu, Jiancheng and Liu, Gaowen and Hong, Mingyi and Chang, Shiyu and Liu, Sijia},booktitle={Thirty-seventh Conference on Neural Information Processing Systems},year={2023},post={https://pruning.netlify.app/},}
ICCV’23
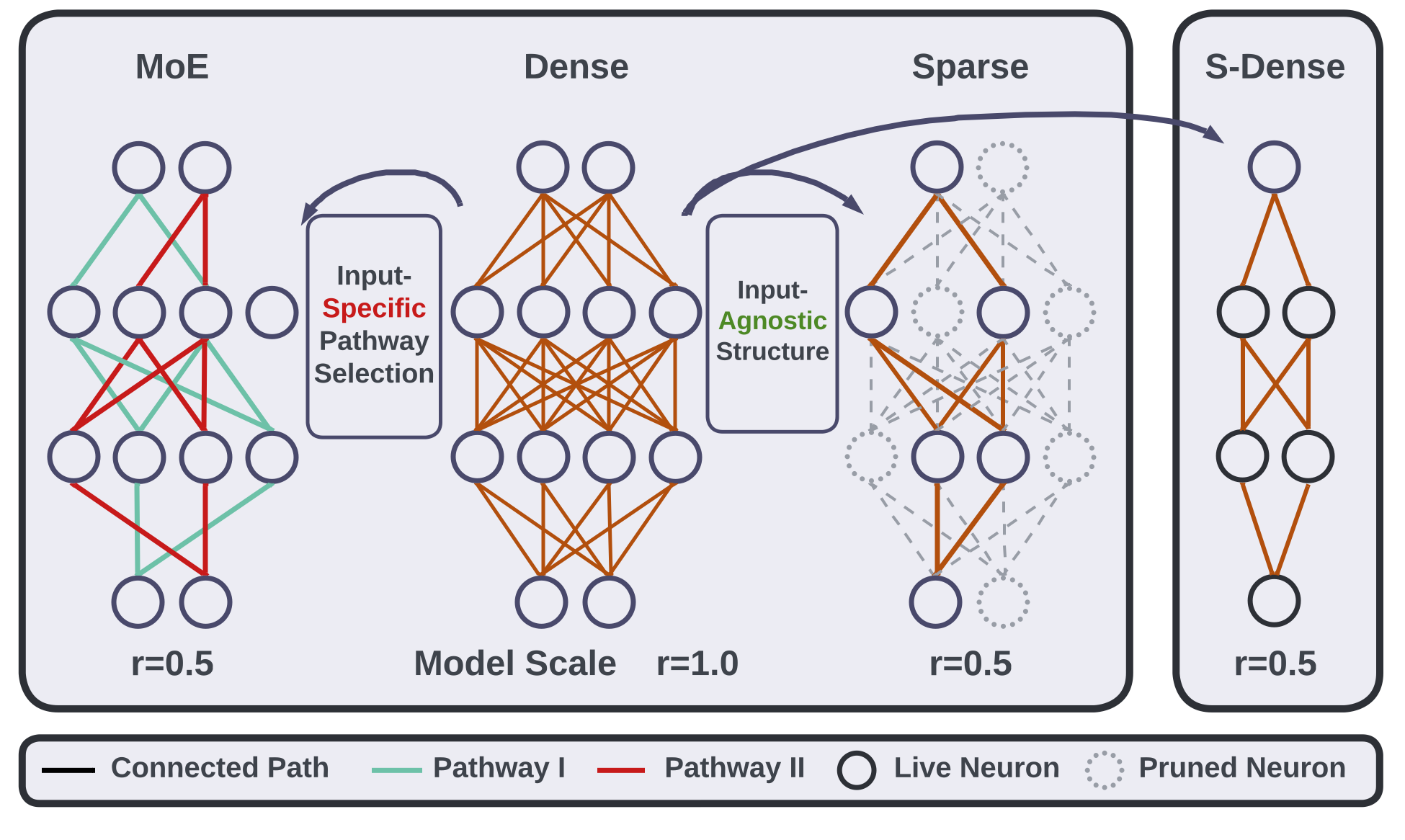
Robust Mixture-of-Expert Training for Convolutional Neural Networks
Yihua Zhang, Ruisi Cai, Tianlong Chen, Guanhua Zhang, Huan Zhang, Pin-Yu Chen, Shiyu Chang, Zhangyang Wang, and Sijia Liu
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Oct 2023
Sparsely-gated Mixture of Expert (MoE), an emerging deep model architecture, has demonstrated a great promise to enable high-accuracy and ultra-efficient model inference. Despite the growing popularity of MoE, little work investigated its potential to advance convolutional neural networks (CNNs), especially in the plane of adversarial robustness. Since the lack of robustness has become one of the main hurdles for CNNs, in this paper we ask: How to adversarially robustify a CNN-based MoE model? Can we robustly train it like an ordinary CNN model? Our pilot study shows that the conventional adversarial training (AT) mechanism (developed for vanilla CNNs) no longer remains effective to robustify an MoE-CNN. To better understand this phenomenon, we dissect the robustness of an MoE-CNN into two dimensions: Robustness of routers (i.e., gating functions to select data-specific experts) and robustness of experts (i.e., the router-guided pathways defined by the subnetworks of the backbone CNN). Our analyses show that routers and experts are hard to adapt to each other in the vanilla AT. Thus, we propose a new router-expert alternating Adversarial training framework for MoE, termed AdvMoE. The effectiveness of our proposal is justified across 4 commonly-used CNN model architectures over 4 benchmark datasets. We find that AdvMoE achieves 1% 4% adversarial robustness improvement over the original dense CNN, and enjoys the efficiency merit of sparsity-gated MoE, leading to more than 50% inference cost reduction.
@inproceedings{zhang2023robust,title={Robust Mixture-of-Expert Training for Convolutional Neural Networks},author={Zhang, Yihua and Cai, Ruisi and Chen, Tianlong and Zhang, Guanhua and Zhang, Huan and Chen, Pin-Yu and Chang, Shiyu and Wang, Zhangyang and Liu, Sijia},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},month=oct,year={2023}}
ICML’23
Linearly Constrained Bilevel Optimization: A Smoothed Implicit Gradient Approach
Prashant Khanduri, Ioannis Tsaknakis, Yihua Zhang, Jia Liu, Sijia Liu, Jiawei Zhang, and Mingyi Hong
In Proceedings of the 40th International Conference on Machine Learning Oct 2023
This work develops analysis and algorithms for solving a class of bilevel optimization problems where the lower-level (LL) problems have linear constraints. Most of the existing approaches for constrained bilevel problems rely on value function-based approximate reformulations, which suffer from issues such as non-convex and non-differentiable constraints. In contrast, in this work, we develop an implicit gradient-based approach, which is easy to implement, and is suitable for machine learning applications. We first provide an in-depth understanding of the problem, by showing that the implicit objective for such problems is in general non-differentiable. However, if we add some small (linear) perturbation to the LL objective, the resulting implicit objective becomes differentiable almost surely. This key observation opens the door for developing (deterministic and stochastic) gradient-based algorithms similar to the state-of-the-art ones for unconstrained bi-level problems. We show that when the implicit function is assumed to be strongly-convex, convex, and weakly-convex, the resulting algorithms converge with guaranteed rate. Finally, we experimentally corroborate the theoretical findings and evaluate the performance of the proposed framework on numerical and adversarial learning problems.
@inproceedings{khanduri2023linearly,title={Linearly Constrained Bilevel Optimization: A Smoothed Implicit Gradient Approach},author={Khanduri, Prashant and Tsaknakis, Ioannis and Zhang, Yihua and Liu, Jia and Liu, Sijia and Zhang, Jiawei and Hong, Mingyi},booktitle={Proceedings of the 40th International Conference on Machine Learning},year={2023},publisher={PMLR}}
ICASSP’23
Robustness-Preserving Lifelong Learning Via Dataset Condensation
Jinghan Jia, Yihua Zhang, Dogyoon Song, Sijia Liu, and Alfred Hero
In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Oct 2023
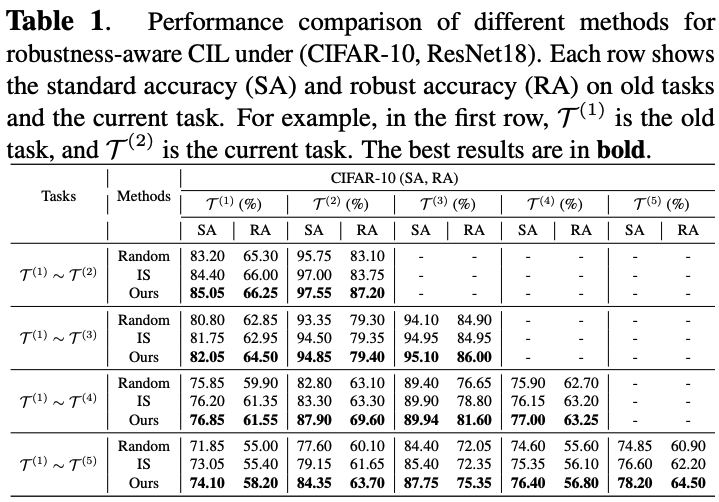
Lifelong learning (LL) aims to improve a predictive model as the data source evolves continuously. Most work in this learning paradigm has focused on resolving the problem of ‘catastrophic forgetting,’ which refers to a notorious dilemma between improving model accuracy over new data and retaining accuracy over previous data. Yet, it is also known that machine learning (ML) models can be vulnerable in the sense that even tiny, adversarial input perturbations can deceive the models into producing erroneous predictions. This motivates the research objective of this paper – specification of a new LL framework that can salvage model robustness (against adversarial attacks) from catastrophic forgetting. Specifically, we propose a new memory-replay LL strategy that leverages modern bi-level optimization techniques to determine the ‘coreset’ of the current data (i.e., a small amount of data to be memorized) for ease of preserving adversarial robustness over time. We term the resulting LL framework ‘Data-Efficient RobustnessPreserving LL’ (DERPLL). The effectiveness of DERPLL is evaluated for class-incremental image classification using ResNet-18 over the CIFAR-10 dataset. Experimental results show that DERPLL outperforms the conventional coresetguided LL baseline and achieves a substantial improvement in both standard accuracy and robust accuracy.
CVPRW’23
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Haomin Zhuang, Yihua Zhang, and Sijia Liu
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops Jun 2023
Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem’query-free attack generation’. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, eg, the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content.
@inproceedings{zhuang2023pilot,title={A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion},author={Zhuang, Haomin and Zhang, Yihua and Liu, Sijia},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},month=jun,year={2023},pages={2384-2391}}
CVPR’23
Understanding and Improving Visual Prompting: A Label-Mapping Perspective
Aochuan Chen, Yuguang Yao, Pin-Yu Chen, Yihua Zhang, and Sijia Liu
In The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 Jun 2023
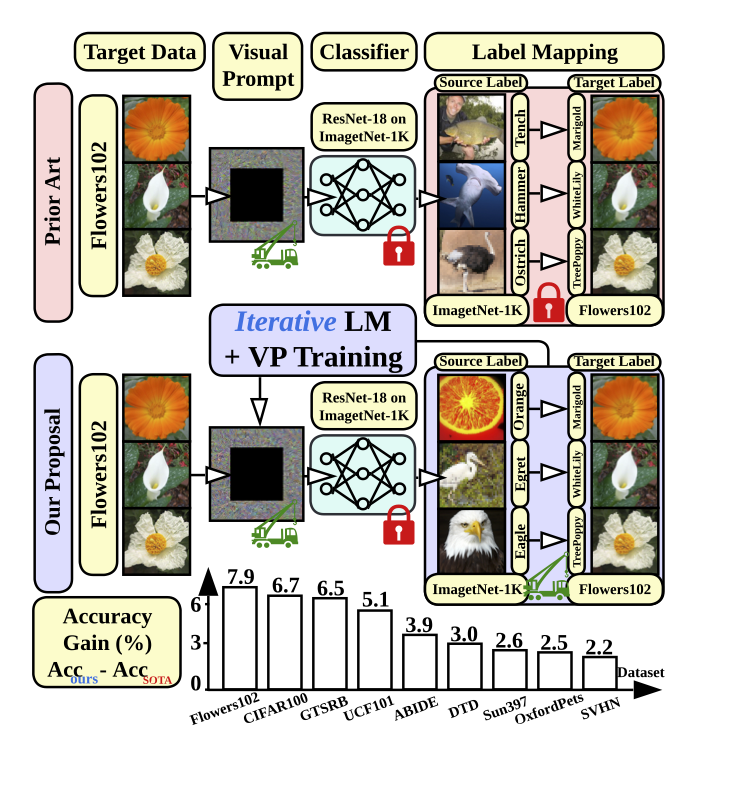
We revisit and advance visual prompting (VP), an input prompting technique for vision tasks. VP can reprogram a fixed, pre-trained source model to accomplish downstream tasks in the target domain by simply incorporating universal prompts (in terms of input perturbation patterns) into downstream data points. Yet, it remains elusive why VP stays effective even given a ruleless label mapping (LM) between the source classes and the target classes. Inspired by the above, we ask: How is LM interrelated with VP? And how to exploit such a relationship to improve its accuracy on target tasks? We peer into the influence of LM on VP and provide an affirmative answer that a better ’quality’ of LM (assessed by mapping precision and explanation) can consistently improve the effectiveness of VP. This is in contrast to the prior art where the factor of LM was missing. To optimize LM, we propose a new VP framework, termed ILM-VP (iterative label mapping-based visual prompting), which automatically re-maps the source labels to the target labels and progressively improves the target task accuracy of VP. Further, when using a contrastive language-image pretrained (CLIP) model, we propose to integrate an LM process to assist the text prompt selection of CLIP and to improve the target task accuracy. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VP methods. As highlighted below, we show that when reprogramming an ImageNet-pretrained ResNet-18 to 13 target tasks, our method outperforms baselines by a substantial margin, e.g., 7.9% and 6.7% accuracy improvements in transfer learning to the target Flowers102 and CIFAR100 datasets. Besides, our proposal on CLIP-based VP provides 13.7% and 7.1% accuracy improvements on Flowers102 and DTD respectively.
@inproceedings{chen2022understanding,title={Understanding and Improving Visual Prompting: A Label-Mapping Perspective},author={Chen, Aochuan and Yao, Yuguang and Chen, Pin-Yu and Zhang, Yihua and Liu, Sijia},booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023},year={2023}}
ICLR’23
TextGrad: Advancing Robustness Evaluation in NLP by Gradient-Driven Optimization
Bairu Hou, Jinghan Jia*, Yihua Zhang*, Guanhua Zhang*, Yang Zhang, Sijia Liu, and Shiyu Chang
In Eleventh International Conference on Learning Representations Jun 2023
Robustness evaluation against adversarial examples has become increasingly important to unveil the trustworthiness of the prevailing deep models in natural language processing (NLP). However, in contrast to the computer vision domain where the first-order projected gradient descent (PGD) is used as the benchmark approach to generate adversarial examples for robustness evaluation, there lacks a principled first-order gradient-based robustness evaluation framework in NLP. The emerging optimization challenges lie in 1) the discrete nature of textual inputs together with the strong coupling between the perturbation location and the actual content, and 2) the additional constraint that the perturbed text should be fluent and achieve a low perplexity under a language model. These challenges make the development of PGD-like NLP attacks difficult. To bridge the gap, we propose TextGrad, a new attack generator using gradient-driven optimization, supporting high-accuracy and high-quality assessment of adversarial robustness in NLP. Specifically, we address the aforementioned challenges in a unified optimization framework. And we develop an effective convex relaxation method to co-optimize the continuously-relaxed site selection and perturbation variables and leverage an effective sampling method to establish an accurate mapping from the continuous optimization variables to the discrete textual perturbations. Moreover, as a first-order attack generation method, TextGrad can be baked into adversarial training to further improve the robustness of NLP models. Extensive experiments are provided to demonstrate the effectiveness of TextGrad not only in attack generation for robustness evaluation but also in adversarial defense.
@inproceedings{hou2022textgrad,title={TextGrad: Advancing Robustness Evaluation in NLP by Gradient-Driven Optimization},author={Hou, Bairu and Jia*, Jinghan and Zhang*, Yihua and Zhang*, Guanhua and Zhang, Yang and Liu, Sijia and Chang, Shiyu},booktitle={Eleventh International Conference on Learning Representations},year={2023}}
ICLR’23
What Is Missing in IRM Training and Evaluation? Challenges and Solutions
Yihua Zhang, Pranay Sharma, Parikshit Ram, Mingyi Hong, Kush Varshney, and Sijia Liu
In Eleventh International Conference on Learning Representations Jun 2023
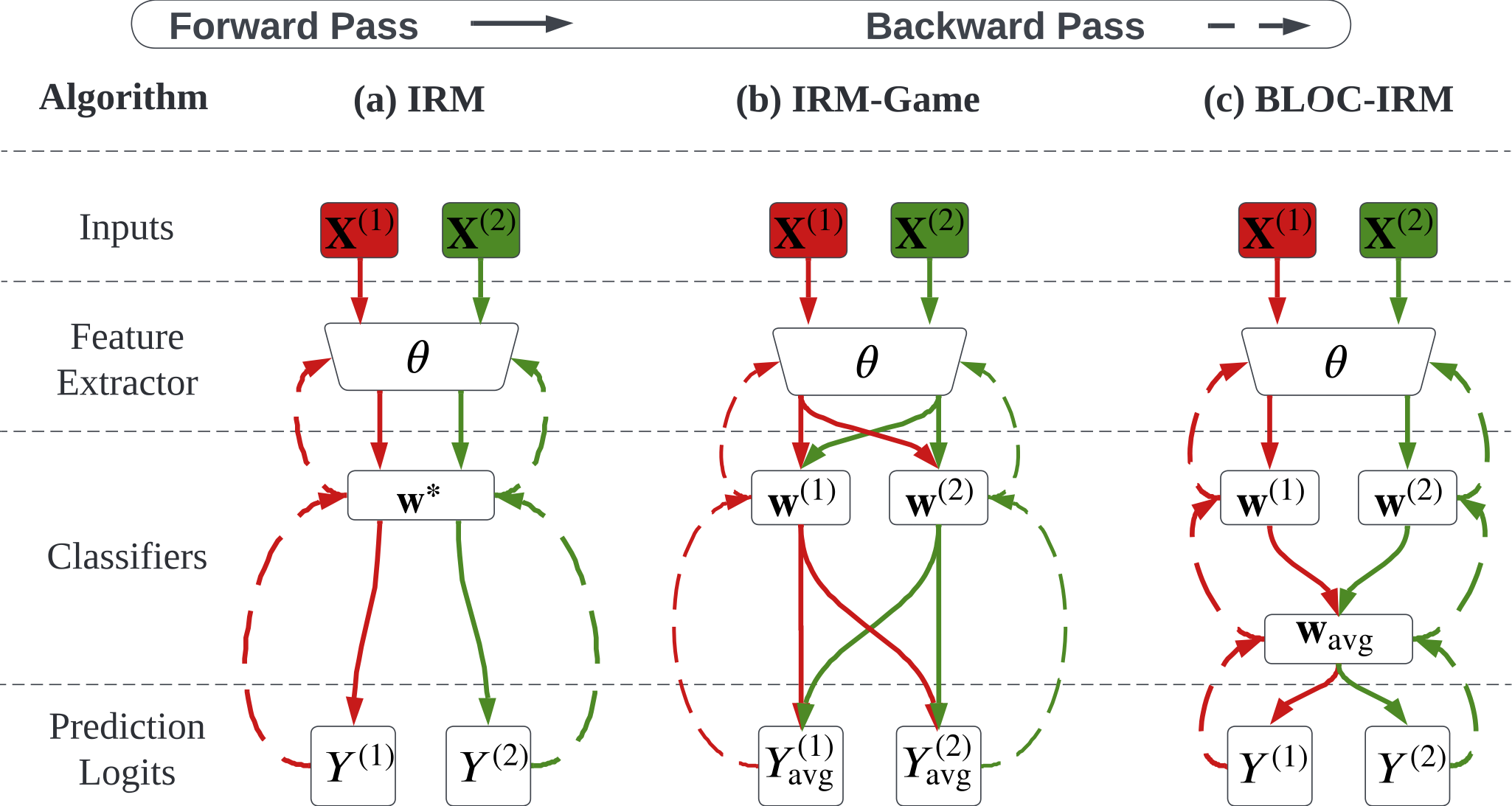
Invariant risk minimization (IRM) has received increasing attention as a way to acquire environment-agnostic data representations and predictions, and as a principled solution for preventing spurious correlations from being learned and for improving models’ out-of-distribution generalization. Yet, recent works have found that the optimality of the originally-proposed IRM optimization (IRM) may be compromised in practice or could be impossible to achieve in some scenarios. Therefore, a series of advanced IRM algorithms have been developed that show practical improvement over IRM. In this work, we revisit these recent IRM advancements, and identify and resolve three practical limitations in IRM training and evaluation. First, we find that the effect of batch size during training has been chronically overlooked in previous studies, leaving room for further improvement. We propose small-batch training and highlight the improvements over a set of large-batch optimization techniques. Second, we find that improper selection of evaluation environments could give a false sense of invariance for IRM. To alleviate this effect, we leverage diversified test-time environments to precisely characterize the invariance of IRM when applied in practice. Third, we revisit (Ahuja et al. (2020))’s proposal to convert IRM into an ensemble game and identify a limitation when a single invariant predictor is desired instead of an ensemble of individual predictors. We propose a new IRM variant to address this limitation based on a novel viewpoint of ensemble IRM games as consensus-constrained bi-level optimization. Lastly, we conduct extensive experiments (covering 7 existing IRM variants and 7 datasets) to justify the practical significance of revisiting IRM training and evaluation in a principled manner.
@inproceedings{zhang2023what,title={What Is Missing in IRM Training and Evaluation? Challenges and Solutions},author={Zhang, Yihua and Sharma, Pranay and Ram, Parikshit and Hong, Mingyi and Varshney, Kush and Liu, Sijia},booktitle={Eleventh International Conference on Learning Representations},year={2023}}
2022
NeurIPS’22
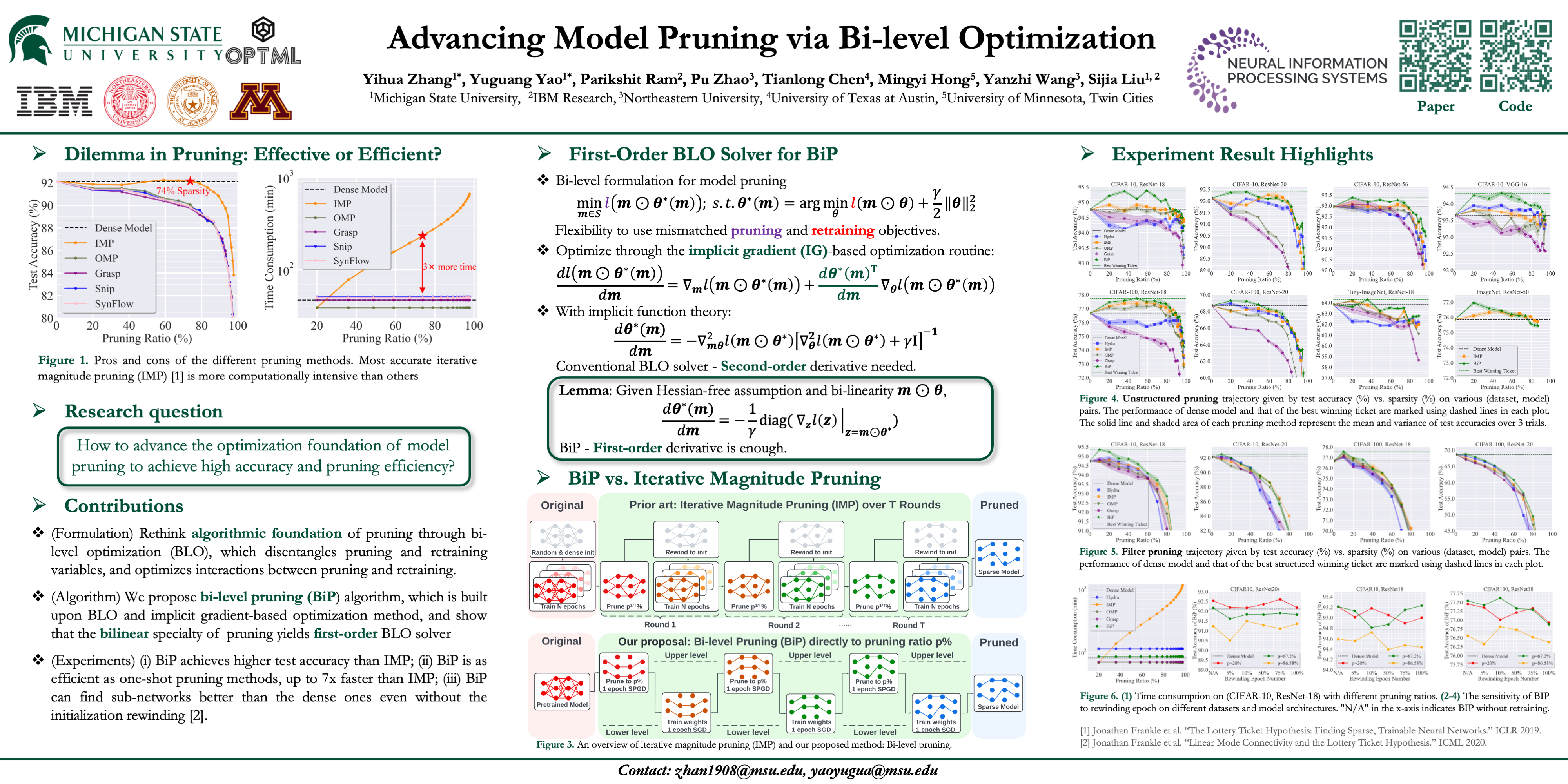
Advancing Model Pruning via Bi-level Optimization
Yihua Zhang*, Yuguang Yao*, Parikshit Ram, Pu Zhao, Tianlong Chen, Mingyi Hong, Yanzhi Wang, and Sijia Liu
In Thirty-sixth Conference on Neural Information Processing Systems Jun 2022
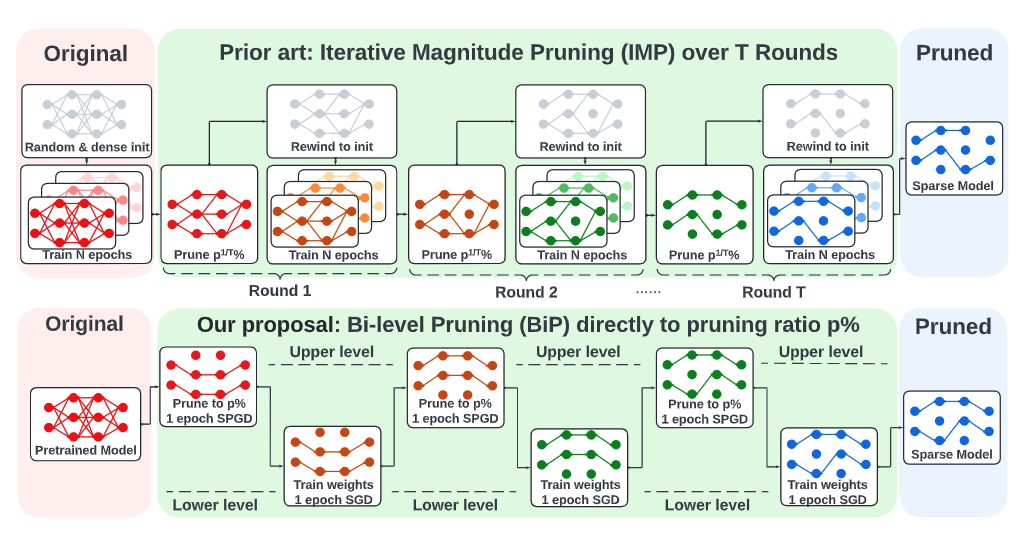
The deployment constraints in practical applications necessitate the pruning of large-scale deep learning models, i.e., promoting their weight sparsity. As illustrated by the Lottery Ticket Hypothesis (LTH), pruning also has the potential of improving their generalization ability. At the core of LTH, iterative magnitude pruning (IMP) is the predominant pruning method to successfully find ‘winning tickets’. Yet, the computation cost of IMP grows prohibitively as the targeted pruning ratio increases. To reduce the computation overhead, various efficient ‘one-shot’ pruning methods have been developed, but these schemes are usually unable to find winning tickets as good as IMP. This raises the question of how to close the gap between pruning accuracy and pruning efficiency? To tackle it, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BiP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BiP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. Through extensive experiments on both structured and unstructured pruning with 5 model architectures and 4 data sets, we demonstrate that BiP can find better winning tickets than IMP in most cases, and is computationally as efficient as the one-shot pruning schemes, demonstrating 2-7\times speedup over IMP for the same level of model accuracy and sparsity.
@inproceedings{zhang2022advancing,title={Advancing Model Pruning via Bi-level Optimization},video={https://youtu.be/eeKITiOOTaE},author={Zhang*, Yihua and Yao*, Yuguang and Ram, Parikshit and Zhao, Pu and Chen, Tianlong and Hong, Mingyi and Wang, Yanzhi and Liu, Sijia},booktitle={Thirty-sixth Conference on Neural Information Processing Systems},year={2022}}
NeurIPS’22
Fairness Reprogramming
Guanhua Zhang*, Yihua Zhang*, Yang Zhang, Wenqi Fan, Qing Li, Sijia Liu, and Shiyu Chang
In Thirty-sixth Conference on Neural Information Processing Systems Jun 2022
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
@inproceedings{zhang2022fairness,title={Fairness Reprogramming},author={Zhang*, Guanhua and Zhang*, Yihua and Zhang, Yang and Fan, Wenqi and Li, Qing and Liu, Sijia and Chang, Shiyu},booktitle={Thirty-sixth Conference on Neural Information Processing Systems},year={2022},}
UAI’22
Distributed Adversarial Training to Robustify Deep Neural Networks at Scale
Gaoyuan Zhang*, Songtao Lu*, Yihua Zhang, Xiangyi Chen, Pin-Yu Chen, Quanfu Fan, Lee Martie, Lior Horesh, Mingyi Hong, and Sijia Liu
In Uncertainty in Artificial Intelligence Jun 2022
Current deep neural networks (DNNs) are vulnerable to adversarial attacks, where adversarial perturbations to the inputs can change or manipulate classification. To defend against such attacks, an effective and popular approach, known as adversarial training (AT), has been shown to mitigate the negative impact of adversarial attacks by virtue of a min-max robust training method. While effective, it remains unclear whether it can successfully be adapted to the distributed learning context. The power of distributed optimization over multiple machines enables us to scale up robust training over large models and datasets. Spurred by that, we propose distributed adversarial training (DAT), a large-batch adversarial training framework implemented over multiple machines. We show that DAT is general, which supports training over labeled and unlabeled data, multiple types of attack generation methods, and gradient compression operations favored for distributed optimization. Theoretically, we provide, under standard conditions in the optimization theory, the convergence rate of DAT to the first-order stationary points in general non-convex settings. Empirically, we demonstrate that DAT either matches or outperforms state-of-the-art robust accuracies and achieves a graceful training speedup (e.g., on ResNet-50 under ImageNet).
@inproceedings{zhang2022distributed,title={Distributed Adversarial Training to Robustify Deep Neural Networks at Scale},author={Zhang*, Gaoyuan and Lu*, Songtao and Zhang, Yihua and Chen, Xiangyi and Chen, Pin-Yu and Fan, Quanfu and Martie, Lee and Horesh, Lior and Hong, Mingyi and Liu, Sijia},booktitle={Uncertainty in Artificial Intelligence},year={2022}}
ICML’22
Revisiting and Advancing Fast Adversarial Training Through The Lens of Bi-Level Optimization
Yihua Zhang*, Guanhua Zhang*, Prashant Khanduri, Mingyi Hong, Shiyu Chang, and Sijia Liu
In Proceedings of the 39th International Conference on Machine Learning Jun 2022
Adversarial training (AT) is a widely recognized defense mechanism to gain the robustness of deep neural networks against adversarial attacks. It is built on min-max optimization (MMO), where the minimizer (i.e., defender) seeks a robust model to minimize the worst-case training loss in the presence of adversarial examples crafted by the maximizer (i.e., attacker). However, the conventional MMO method makes AT hard to scale. Thus, Fast-AT and other recent algorithms attempt to simplify MMO by replacing its maximization step with the single gradient sign-based attack generation step. Although easy to implement, FAST-AT lacks theoretical guarantees, and its empirical performance is unsatisfactory due to the issue of robust catastrophic overfitting when training with strong adversaries. In this paper, we advance Fast-AT from the fresh perspective of bi-level optimization (BLO). We first show that the commonly-used Fast-AT is equivalent to using a stochastic gradient algorithm to solve a linearized BLO problem involving a sign operation. However, the discrete nature of the sign operation makes it difficult to understand the algorithm performance. Inspired by BLO, we design and analyze a new set of robust training algorithms termed Fast Bi-level AT (Fast-BAT), which effectively defends sign-based projected gradient descent (PGD) attacks without using any gradient sign method or explicit robust regularization. In practice, we show that our method yields substantial robustness improvements over multiple baselines across multiple models and datasets.
@inproceedings{zhang2022revisiting,title={Revisiting and Advancing Fast Adversarial Training Through The Lens of Bi-Level Optimization},author={Zhang*, Yihua and Zhang*, Guanhua and Khanduri, Prashant and Hong, Mingyi and Chang, Shiyu and Liu, Sijia},booktitle={Proceedings of the 39th International Conference on Machine Learning},pages={26693--26712},year={2022},publisher={PMLR}}
CVPR’22
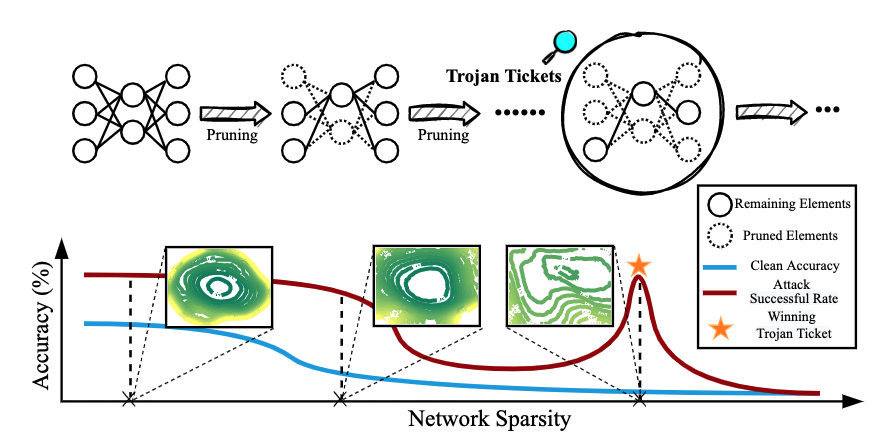
Quarantine: Sparsity Can Uncover the Trojan Attack Trigger for Free
Tianlong Chen*, Zhenyu Zhang*, Yihua Zhang*, Shiyu Chang, Sijia Liu, and Zhangyang Wang
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Jun 2022
Trojan attacks threaten deep neural networks (DNNs) by poisoning them to behave normally on most samples, yet to produce manipulated results for inputs attached with a particular trigger. Several works attempt to detect whether a given DNN has been injected with a specific trigger during the training. In a parallel line of research, the lottery ticket hypothesis reveals the existence of sparse subnetworks which are capable of reaching competitive performance as the dense network after independent training. Connecting these two dots, we investigate the problem of Trojan DNN detection from the brand new lens of sparsity, even when no clean training data is available. Our crucial observation is that the Trojan features are significantly more stable to network pruning than benign features. Leveraging that, we propose a novel Trojan network detection regime: first locating a "winning Trojan lottery ticket" which preserves nearly full Trojan information yet only chance-level performance on clean inputs; then recovering the trigger embedded in this already isolated subnetwork. Extensive experiments on various datasets, i.e., CIFAR-10, CIFAR-100, and ImageNet, with different network architectures, i.e., VGG-16, ResNet-18, ResNet-20s, and DenseNet-100 demonstrate the effectiveness of our proposal.
@inproceedings{chen2022quarantine,title={Quarantine: Sparsity Can Uncover the Trojan Attack Trigger for Free},author={Chen*, Tianlong and Zhang*, Zhenyu and Zhang*, Yihua and Chang, Shiyu and Liu, Sijia and Wang, Zhangyang},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},pages={598--609},year={2022}}


{kind=link}